
Introduction As artificial intelligence continues its rapid evolution, organizations face an expanding landscape of tools, platforms, and architectural patterns. From the foundational building blocks of compute infrastructure and large language models to the sophisticated multi‐agent systems that orchestrate tasks on our behalf, the modern AI ecosystem has never been more versatile—or more complex. In this article, we’ll explore three critical facets of this landscape:

- AI Ecosystem Overview – A high-level look at the layers that power AI, from infrastructure to user interfaces.2. Retrieval-Augmented Generation (RAG) Architectures – How advanced retrieval techniques blend with generative models to produce more accurate, context‐aware outputs.3. AI Agents Stack – The end‐to‐end solutions that bring together vertical agents, hosting platforms, memory stores, observability tools, and more to deliver robust, domain‐specific AI experiences.
Whether you’re a machine learning engineer, product manager, or simply curious about how AI can enhance your industry, understanding these layers, architectures, and platforms is vital for building reliable and future‐proof AI solutions.
CyberGPT Store - AI Assistants for Cybersecurity | CyberGPT StoreDiscover specialized AI assistants for modern cybersecurity challenges. From CISO tools to compliance, security testing, and more. 🛡️ CyberGPT Store
🛡️ CyberGPT Store
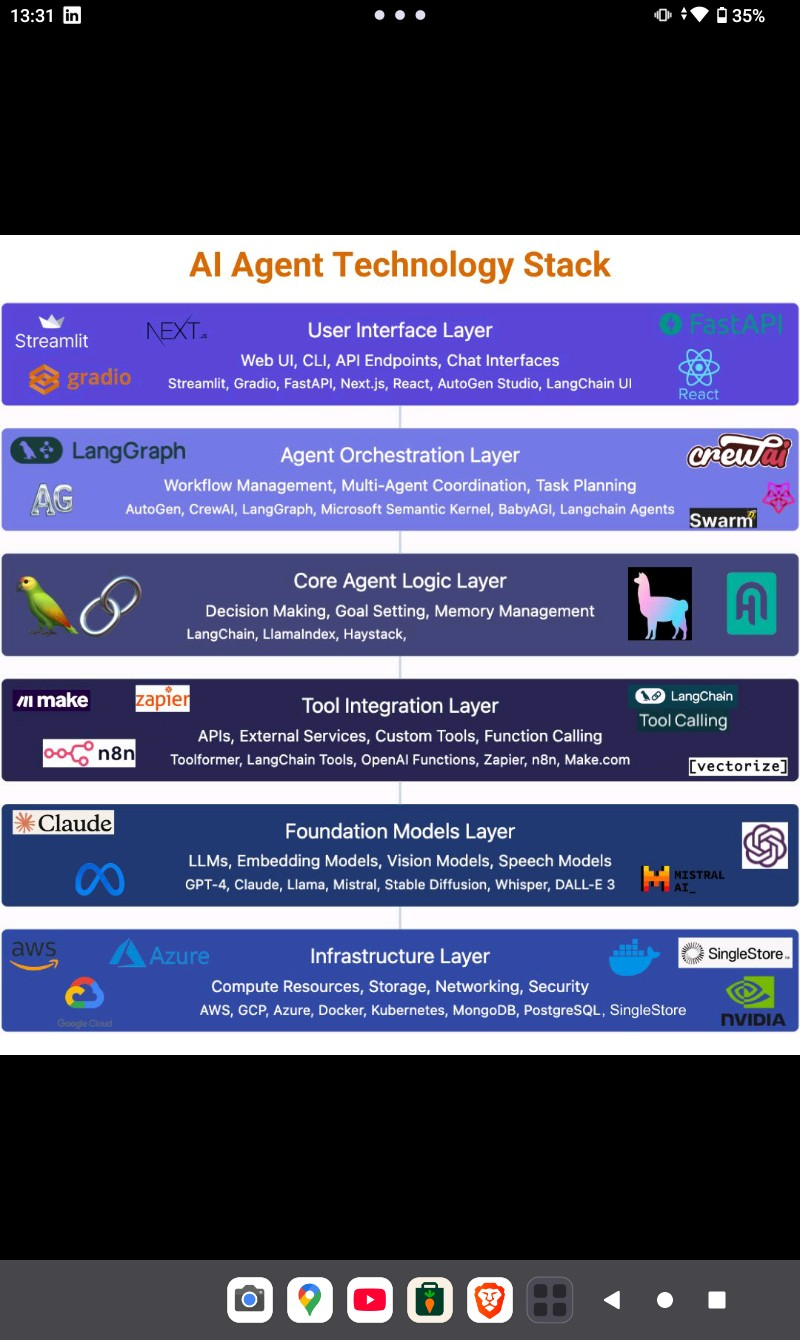
1. Infrastructure Layer
What it is:
- The physical and virtual backbone that AI runs on, including cloud providers, containerization platforms, and databases.- Examples: AWS, Google Cloud, Azure, Docker, Kubernetes, MongoDB, PostgreSQL, SingleStore.
What it does:
- Compute resources: High-performance CPUs and GPUs (often from NVIDIA) for training and inference.- Storage and networking: Data storage solutions and networking to handle large datasets, ensuring low-latency communication.- Security: Mechanisms for data encryption, access control, and compliance with regulations.
Effectively, the Infrastructure Layer supplies the raw horsepower and reliability needed to support massive model training and deployment.
AI Weekly Roundup: Major Industry Moves Reshape the LandscapeArtificial Intelligence (AI) has undergone a remarkable transformation since its inception, evolving from theoretical concepts to practical applications that are deeply embedded in our daily lives. The journey of AI is a testament to human ingenuity and technological advancement, driven by a relentless pursuit of intelligence that can mimic, augment, Hacker Noob TipsHacker Noob Tips
Hacker Noob TipsHacker Noob Tips
2. Foundation Models Layer
What it is:
- Large-scale pre-trained models and all their variants, covering text, images, and speech.- Examples: GPT-4, Claude, Llama, Mistral, Stable Diffusion, Whisper, DALL‑E 3.
What it does:
- Core intelligence: These models are “foundational” because they can be adapted (fine-tuned or prompted) to perform many tasks with minimal additional training data.- Multimodal capabilities: Beyond text, some of these models handle images, speech, or video.- Continuous updates: This space moves fast—new model architectures and fine-tuned variants appear frequently, offering improvements in speed, accuracy, or domain specialization.
3. Tool Integration Layer
What it is:
- A set of connectors, APIs, and “function calling” mechanisms that allow models to interact with the outside world.- Examples: Make, Zapier, n8n, LangChain Tools, OpenAI Functions, vector indexing libraries.
What it does:
- External services: Let AI agents call a wide variety of services—CRMs, databases, SaaS platforms—to retrieve or update information.- Custom toolchains: Build specialized workflows for tasks like data extraction, email automation, or file transformation.- Function calling: The newest generation of large language models can call registered “functions” (APIs) directly when they need to access structured data or perform a specific task.
4. Core Agent Logic Layer
What it is:
- The “brain” of an AI agent—where it decides what to do next, retains context and memory, and applies logic to solve complex problems.- Examples: LangChain, LlamaIndex, Haystack.
What it does:
- Decision-making and goal setting: Agents break down high-level goals into actionable plans, deciding which functions or tools to call.- Memory management: Storing and retrieving relevant context so the agent can maintain coherence over longer conversations or tasks.- Knowledge retrieval: Integrating with vector databases or indexes to fetch domain-specific knowledge.
5. Agent Orchestration Layer
What it is:
- Coordinates multiple agents or workflows, handling more advanced needs like multi-agent collaboration, complex task sequencing, and concurrency.- Examples: AutoGen, CrewAI, LangGraph, Microsoft Semantic Kernel, BabyAGI, Swarm.
What it does:
- Workflow management: Allows you to define complex sequences of tasks carried out by different AI agents, each specialized for certain subtasks.- Multi-agent coordination: Agents can “talk” to one another or share data, collectively solving bigger tasks.- Task planning: Automates the planning of steps and resource allocation, so an AI project can scale or branch out as needed.
6. User Interface Layer
What it is:
- The “front end” through which humans interact with AI systems, whether via a web app, command-line interface, or direct API calls.- Examples: Streamlit, Gradio, FastAPI, Next.js, React, AutoGen Studio, LangChain UI.
What it does:
- Input and output: Provides simple ways for users to type questions, upload files, or interact with a chatbot or application.- Customization: Lets developers or product owners tailor the user experience, adding features like conversation history, result visualization, or authentication.- APIs and endpoints: For programmatic interactions—other software can consume the AI’s capabilities without going through a web interface.
Bringing It All Together
An AI solution typically relies on every one of these layers to function smoothly:
- Infrastructure provisions the compute, storage, and security environment.2. Foundation Models supply the AI capabilities (language, vision, etc.).3. Tool Integrations let the AI agent connect to external apps and data sources.4. Core Agent Logic figures out how to solve the user’s request using those tools and the relevant data.5. Agent Orchestration coordinates multiple subagents or tasks for larger workflows.6. User Interface turns these behind-the-scenes processes into an accessible experience for the end user.
As the ecosystem matures, we see growing specialization at each layer—alongside better interoperability between layers. This layered architecture helps developers and organizations mix and match solutions, enabling faster innovation and more robust AI-driven products. The result is an ever-evolving, vibrant AI ecosystem capable of tackling diverse use cases across industries and domains.
Revolutionizing Cybersecurity with AI: An In-Depth Look at Cyber Agent ExchangeIn the ever-evolving field of cybersecurity, artificial intelligence (AI) has become a crucial component in enhancing digital defense mechanisms. Two platforms exemplifying this integration are Cyber Agent Exchange and CyberGPT Store, each offering unique AI-driven solutions to address modern cybersecurity challenges. Overview of Cyber Agent Exchange Cyber Agent Exchange is![]() Hacker Noob TipsHacker Noob Tips
Hacker Noob TipsHacker Noob Tips
 This image illustrates a variety of Retrieval-Augmented Generation (RAG) architectures—ways to combine a large language model with external retrieval sources to produce more accurate or contextually‐grounded responses. Each diagram highlights a different strategy for how to retrieve and filter relevant information before the model generates an answer.
This image illustrates a variety of Retrieval-Augmented Generation (RAG) architectures—ways to combine a large language model with external retrieval sources to produce more accurate or contextually‐grounded responses. Each diagram highlights a different strategy for how to retrieve and filter relevant information before the model generates an answer.
Key Concepts in RAG
- Query – The user prompt or question.2. Documents/Chunks – Source content that has been segmented (chunked) or otherwise indexed.3. Vector Database / Graph Database – Where embeddings and relationships are stored so relevant documents can be retrieved.4. Generative Model (LLM) – The large language model that synthesizes an answer using retrieved context.5. Embedding Model – Converts text (and sometimes other data modalities) into numerical vectors for similarity search.6. Re‐ranker – A model or algorithm that scores retrieved documents to pick the most relevant ones.7. Agentic Components – Modules (or entire agents) that reason about how to perform retrieval, re‐ranking, or even route the user query to different tools.
1. Naive RAG
- Flow: User query → retrieval of top relevant chunks → LLM generates the response.- Key characteristic: The simplest approach—whatever the retrieval step returns is directly given to the model.
When to use
- Good for straightforward question–answering where a single vector database is enough.- Lower complexity, but also more prone to retrieving off-topic or low‐quality chunks.
2. Retrieve‐and‐rerank
- Flow: User query → retrieve potential chunks → re‐rank the chunks → feed top‐ranked chunks into LLM.- Key characteristic: Incorporates a re‐ranker (which can be another smaller model or a specialized technique) that scores candidates to further refine results.
When to use
- Helps ensure only the most relevant information reaches the LLM.- Particularly useful if the initial retrieval step often returns many “okay-ish” chunks and you need a second pass to pick the best.
3. Multimodal RAG
- Flow: Instead of just text documents, you can retrieve images, audio, or other media.- Key characteristic: Uses a multimodal embedding model that can handle different data types, or separate pipelines for each modality.
When to use
- You have a variety of content types (e.g., text, images, or video) and want a single pipeline that can retrieve any relevant content.- Example: A question might require referencing both written documentation and an accompanying image.
4. Graph RAG
- Flow: Retrieval not only from a vector database but also from a graph database, so the system can traverse relationships between entities or documents.- Key characteristic: Leverages knowledge‐graph semantics, letting the system follow links or paths for more complex queries.
When to use
- You have rich structured relationships (e.g., entity A is related to entity B) and want your system to retrieve information by traversing the graph.- Great for domains like scientific research, enterprise knowledge bases, or any large, interlinked corpus.
5. Hybrid RAG
- Flow: Combines both vector‐based retrieval and other specialized retrieval methods (could be a symbolic approach, a knowledge graph, or a classical search engine).- Key characteristic: The best of multiple worlds—often merges vector embeddings with keyword search or knowledge graph lookups.
When to use
- You want a robust approach that covers unstructured text (via vector search) and structured or symbolic data (via classical search or knowledge graph).- Example: Searching a product catalog that has both textual descriptions and well-defined product metadata (like category or brand relationships).
6. Agentic RAG (Router)
- Flow: A “router” agent receives the user’s query and decides which retrieval approach or external tool to invoke. It can call specialized retrieval agents or different vector stores as needed.- Key characteristic: The system orchestrates multiple retrieval endpoints or processes. The router agent picks the best route, collects responses, and returns a unified answer.
When to use
- You have multiple specialized data sources (like separate databases for product info, user manuals, FAQs, etc.).- You want to dynamically choose the correct retrieval strategy based on the query.
7. Agentic RAG (Multi‐Agent RAG)
- Flow: Multiple autonomous agents can (1) each manage its own retrieval, (2) possibly query different tools, and (3) exchange results or instructions with each other before generating a final response.- Key characteristic: A more complex system where each agent is specialized—for example, one handles code searches, another handles support tickets, and another processes images or structured data.
When to use
- Large or intricate use cases where a single retrieval pipeline might be too constrained.- You want specialized “sub‐agents” for different tasks, each with custom rules or domain knowledge, collaborating toward the best final answer.
Why These Variations Matter
- Accuracy & Relevance: RAG solutions aim to ground the model’s responses in real data. Different architectures tackle different needs for filtering, ranking, and combining information.- Complexity vs. Value: More advanced designs (like multi‐agent or hybrid) can yield more robust answers across diverse data sources—but also require more engineering overhead.- Scalability & Maintenance: Systems with multiple retrieval components can be more flexible as your data grows or changes, but orchestration and reliability become bigger concerns.
In Summary
This image is a visual guide to the evolving ecosystem of retrieval‐augmented generation. Each RAG pattern helps ensure that when you query an LLM, it has the right context from relevant documents or data sources. Whether you use a straightforward “Naive RAG” or a multi‐agent approach depends on your data landscape, performance requirements, and how specialized your retrieval needs to be.
 This graphic presents a stack of tools and services used to build, host, and monitor AI agents. It emphasizes how the AI agent ecosystem is moving from just large language models to full, end‐to‐end solutions. Below is a quick overview of the categories shown:
This graphic presents a stack of tools and services used to build, host, and monitor AI agents. It emphasizes how the AI agent ecosystem is moving from just large language models to full, end‐to‐end solutions. Below is a quick overview of the categories shown:
1. Vertical Agents
These are domain‐specific or specialized AI solutions. Think of them as “out‐of‐the‐box” agents purpose‐built for particular industries or tasks.
- Examples: Decagon, Sierra, replit, perplexity, Harvey, MutioN, Lindy- Use Cases: Legal document drafting, software engineering support, or customer service bots.
By focusing on a single domain, they can be more efficient and accurate than a general‐purpose agent.
2. Agent Hosting & Serving
Tools and platforms that help deploy, manage, and scale AI agents in production.
- Examples: Letta, LangGraph, Assistants API, Agents API, Amazon Bedrock Agents, LiveKit Agents- Core Functions: Hosting your agent in a stable environment, handling load balancing, security, updates, and more.
You can see these as the “infrastructure layer” specifically tailored for AI agent lifecycles.
3. Observability
Solutions that measure and monitor your AI agents’ performance, usage patterns, and health.
- Examples: LangSmith, Arize, Weave, LangFuse, AgentOps.ai, Braintrust- Core Functions: Tracking latency, retrieval accuracy, conversation analytics, error logs, and more.
Just like in traditional DevOps, these tools ensure your agents are reliable, secure, and high‐performing.
4. Agent Frameworks
These are libraries and development frameworks for building AI agents from scratch or customizing them heavily.
- Examples: Letta, LangGraph, AutoGen, LlamaIndex, CrewAI, DSPy, phidata, Semantic Kernel, AutoChain- Core Functions: Chain of thought prompting, state management, memory integration, or specialized “pluggable” modules for advanced interactions.
They provide the building blocks to create new agents or expand existing ones to handle more complex workflows.
5. Memory
Specialized modules for storing or retrieving conversational context, user session data, or knowledge over time.
- Examples: MemGPT, zep, LangMem, mem0- Why It Matters: Agents need memory to maintain context across interactions or to recall prior user inputs.
This is distinct from normal databases because it often integrates with vector embeddings or other advanced retrieval strategies.
6. Tool Libraries
Packages or platforms that provide off‐the‐shelf tools that an AI agent can call to accomplish certain tasks (e.g., browsing the web, summarizing text, writing code).
- Examples: Composio, Browserless, Exa- Value Add: They can drastically shorten development time by letting you “plug in” functionalities like PDF parsing, PDF generation, search, or data extraction—without re‐inventing the wheel.
7. Sandboxes
Secure, isolated environments where AI agents can safely run code or perform actions without compromising the host system.
- Examples: E2B, Modal- Use Cases: Agents that need to execute scripts, experiment with user‐provided code, or run sensitive tasks— all with minimal risk to production infrastructure.
8. Model Serving
Platforms and services that host and serve large language models or other AI models (vision, speech, etc.).
- Examples: vLLM, LM Studio, SGL, together.ai, Fireworks AI, groq, OpenAI, Anthropic, Mistral AI, etc.- Role: They provide scalable, reliable inference APIs—so your agents can call a stable endpoint for generating text, images, or other results.
9. Storage
Databases or vector stores designed for embedding large volumes of data and quickly retrieving relevant bits (context) for an agent.
- Examples: Chroma, drant, Pinecone, Weaviate, Neon, Supabase- Purpose: Storing and indexing the knowledge your agent relies on—like user documents, operational data, or domain‐specific corpora.
Why This Matters
This “AI Agents Stack” shows how the ecosystem is no longer just about the core model. We now have specialized tools for:
- Building and customizing agent behavior- Storing and retrieving memory- Observing and optimizing performance- Safely deploying agent code- Integrating domain‐specific knowledge
It’s a sign of how mature AI agent development is becoming—covering everything from hosting and security to domain‐tailored features and observability. Whether you’re in cybersecurity, marketing, or healthcare, there’s likely a tool or platform in this stack to accelerate building and deploying your next AI solution.
Conclusion
Taken together, these three perspectives—ecosystem layers, retrieval‐augmented generation approaches, and the emerging AI agents stack—offer a comprehensive view of where AI stands today. What begins with robust infrastructure and foundational models can be augmented with RAG techniques to boost contextual relevance, and then deployed as full‐blown agent solutions ready to transform countless industries. As AI continues to advance, harnessing the right combination of frameworks, hosting solutions, and specialized retrieval methods will be the key to unlocking its full potential. By adopting an integrated view—one that weaves together the latest tools, best practices, and forward‐looking strategies—you’ll be well‐positioned to create AI systems that stand the test of time and deliver tangible value across domains.


